

DevOps, DataOps and Machine Learning

In this blog I want to explore how DevOps is being applied in the industry today before we really dig in to applying DevOps to Machine Learning in the next blog. If this is the first blog you’re reading, then you might want to start at the beginning.
In recent years there has been a subtle shift appearing in the industry. It has begun to try to take the principles of DevOps and apply them to data analytics. In 2015 Andy Palmer coined the term DataOps, he describes DataOps as the intersection of data engineering, data integration, data quality and data security (Palmer, 2015). I first came across the term form Steph Locke’s blog “DataOps, its a thing. Honest” https://itsalocke.com/blog/dataops–its-a-thing-honest/ .
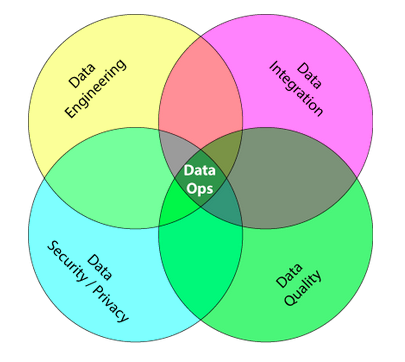
The image above is from Palmer’s blog https://www.tamr.com/from-devops-to-dataops-by-andy-palmer/. It shows DataOps as being the intersection of Data integration, Data quality, data security and data engineer. This is one definition that fits with database management system DevOps, but does not transfer so much to Machine Learning. We will come back to this in the next blog. Since Palmer’s blog in 2015, the term DataOps has increased in popularity. In the image below, you can see that since 2015 there has been a slow by steady increase in the searches for the term DataOps. There is now a DataOps Manifesto, which was created by the creators of the Agile manifesto (Dataopsmanifest, 2017).

DataOps is an agile methodology designed for data-intensive applications, which includes data science and machine learning (Valentine & Merchan, 2017 pp.6). Valentine and Merchan indicate that to deliver DataOps a business needs a DataOps platform which can support the following features:
Enterprise-grade reliability
Support for any data type
Unlimited scalability
Support for distributed architectures, or parallel processing
Full support for machine learning development
In any data science language
Support for a model publication process
Multitenancy
Self-service access to data in a secure manner
(Valentine & Merchan, 2017. Pp 7)
Valentine’s & Merchan’s article on DataOps is focused beyond the development of a machine learning model right in to production. When assessing if a tool production data science tool is fit-for-purpose, this is a good list to start with. A data scientist if often concerned with the problem at hand, developing a machine learning model. The key points listed by Valentine and Merchan are seldom considered by a data scientist and the in the normal skillset required. Valentine and Marchan indicate that DataOps is still an emerging trend, as we can see in figure 4 from Google this is very true. DataOps is different from DevOps and to achieve this you need a DevOps engineer with a data frame of mind (Olavsrud, 2017). The point that Ted Dunning in Thor Olavsrud’s article raises is that the finding DevOps people is quite hard, finding those who know DevOps and Data Science is very hard. To facilitate this a design pattern that handles most of the elements of DevOps is required.
DevOps and DataOps for Machine Learning?
An agile methodology such as DevOps or DataOps is designed to make getting a code in to production quicker with less errors. But as Schutt and O’Neill indicate in their book Doing data science from the frontline this is not an easy task. Scully notes that there are many reasons why machine learning in production is problematic (Scully, 2015), which would make DataOps difficult.
Time constraints to build – The amount of time required to get a model from idea in to production is a lot.
Time constraints once deployed – A model needs to respond in x number of seconds/milliseconds.
Data changes very quickly – A model may fit the business at the time it is trained, then the business may change significantly and the model no longer reflect reality. This is common and happens in most data-intensive applications.
Production machine learning needs to be able to integrate with other applications – Once a model is published there maybe any number of ways it needs to interact with data from the business.
Machine learning needs to be robust – It needs to continue to work in production and require little maintenance.
Live machine learning does not always work as expected – A local model may work well then when published may not have the uplift that was expected.
If one data science team develops in R and the application it is being deployed to work in Java, how do you get these two teams to work together – this is an extension of the development vs operations problem.
Scully’s list and Valentine and Merchan’s summary of requirements for DataOps indicates that model management, the process of moving and maintaining a model in production is difficult to achieve. This project intends to develop an end-to-end DataOps/DevOps pipeline which allows a data scientist to deploy a model in to production without facing the problems described by Valentine and Marchan or Scully.
What types of machine learning will I look at?
Machine learning models come in all shapes and sizes and are optimised for particular problems. A model might be designed to predict a value based on based on other numerical values by fitting a line as is the case with a regression model. Other models look at classification both binary and multi-variate or clustering. Each machine learning model is designed to take a generic model and alter the parameters of that model to give a prediction of some kind.
Ok so in the next blog we will look at doing just that. Applying DevOps to machine learning.