

Databricks SQL Analytics Workspace - The Evolution of the Lakehouse
We have discussed in the past this idea of the lakehouse, the aspirational target of many analytics platforms these days of combining the huge power and potential of data lakes with the rigour, reliability and concurrency of a data warehouse. It’s an interesting concept but has, in the past, been firmly an aspiration.
In the world without lakehouses, we often see the “Modern Data Warehouse”, this two-phased approach to providing a holistic platform – we load our early data into a lake where we shape it and massage it into an understandable state. It is here we perform data science, exploratory data analysis, early sight analytics prototyping and various other functions that don’t quite fit into a data warehouse… but then we load our data into a relational store for serving to the business. This is where we can meet their demands for a rich SQL environment, auditable data models and rigorous change procedures. Essentially, we store data twice so that we can achieve the best of both worlds.
The Modern Data Warehouse
The Lakehouse, as described by Databricks, aims to do away with this redundancy, bringing the various maturities of the data warehouse into the data lake itself. Rather than having two platforms for their different specialisms, grow one central platform to meet the demands of both sides.
The Lakehouse Architecture
But this is an evolving ideal, a moving target as the technology landscape shifts around us. How do we measure success in having achieved this combined, “Lakehouse” approach?
For me – one easy way is to look at the various personas that may interact with this system and how well their needs are met by a single combined platform.
Analytics Personas
Data Scientist – The Lakehouse approach actually plays into the data scientist skill set very well already. The Spark eco-system provides a hugely flexible platform to bring in open-source libraries where they can train models over huge datasets. The functionality around model experimentation tracking, reliability and deployment provided by MLFlow is a huge bonus. In many pure data warehousing solutions, machine learning is an after-thought, plumbed in via awkward extensions, or even via export/score/re-import workarounds.
Data Engineers – Whereas the ETL developer of the past was largely an extension of BI departments, modern data engineers are more technically adept, bringing an understanding of software engineering to the development of robust, performant data pipelines. Spark 3.0, underpinned by the Delta engine, brings a vast array of tools for crafting these pipelines – this is an area where the warehouse area traditionally suffers, making the combined Lakehouse approach more appealing for data engineers.
Data Analysts – The analysts have a deep understanding of their business domain and are usually hot-shot SQL developers, some may have Python or R skills, but it’s certainly not guaranteed. The SQL Analyst wants a rich, interactive SQL environment and certainly won’t be happy with a reduction in functionality. The current Spark SQL offerings in various environments aren’t quite up to scratch – it can be difficult to persuade them that a Spark-based platform is a suitable working environment.
Business Intelligence Developer – The most traditional role in the building of warehouses, the BI developer is concerned about crafting performant data models, managing data and providing a platform for self-service reporting. The functionality provided by the Delta engine, unlocking merge statements, data auditing, transaction rollbacks etc make the Lakehouse a much more viable place to build governed, trusted data models.
Report Consumers – Also known as “the business” by many IT folk, this is a rich and varied persona group, there may be technical skills, there may be absolutely zero. The common factor that binds this persona together is that reporting and analytics is not their primary job function – they need fast, responsive dashboards where they can gain real, actionable insights without a lot of time or technical investment.
What becomes clear as we move through these personas is the gap in functionality when it comes to the less technical users. Given Spark’s origins in the big data community this makes sense. The established toolsets are geared towards Python and Scala developers, people who are very literate in distributed compute for solving complex data problems.
If the Lakehouse approach is truly to be successful, it needs to provide a much richer environment for the SQL user, for the data analyst exploring the data, for the business intelligence developer migrating reporting logic and for the report consumers accessing the environment via external BI tools such as Power BI and Tableau.
Introducing Databricks SQL Analytics
It should be no surprise that the SQL persona is where the next set of Databricks and Delta releases are targeted. We’ve heard rumblings about the development of a new C++ runtime specifically targeted to make query performance faster, along with the acquisition of dashboarding company Redash earlier in the year – we are now seeing the results in a brand new feature, Databricks SQL Analytics.
A New SQL Environment
Firstly, we will be seeing an alternative environment to the familiar notebooks workspace currently available in Databricks. This is a much more SQL-orientated workspace, packed with the familiar features from any SQL IDE such as autocomplete/intellisense, drag and drop metadata exploration, rich visualisations and more. On their own, these features are by no means ground-breaking, but they give the SQL user a home that is just as functionally rich as their other SQL-based environments. This new home has the huge benefit of being backed by the full power of the Spark engine and the data availability of the lake.
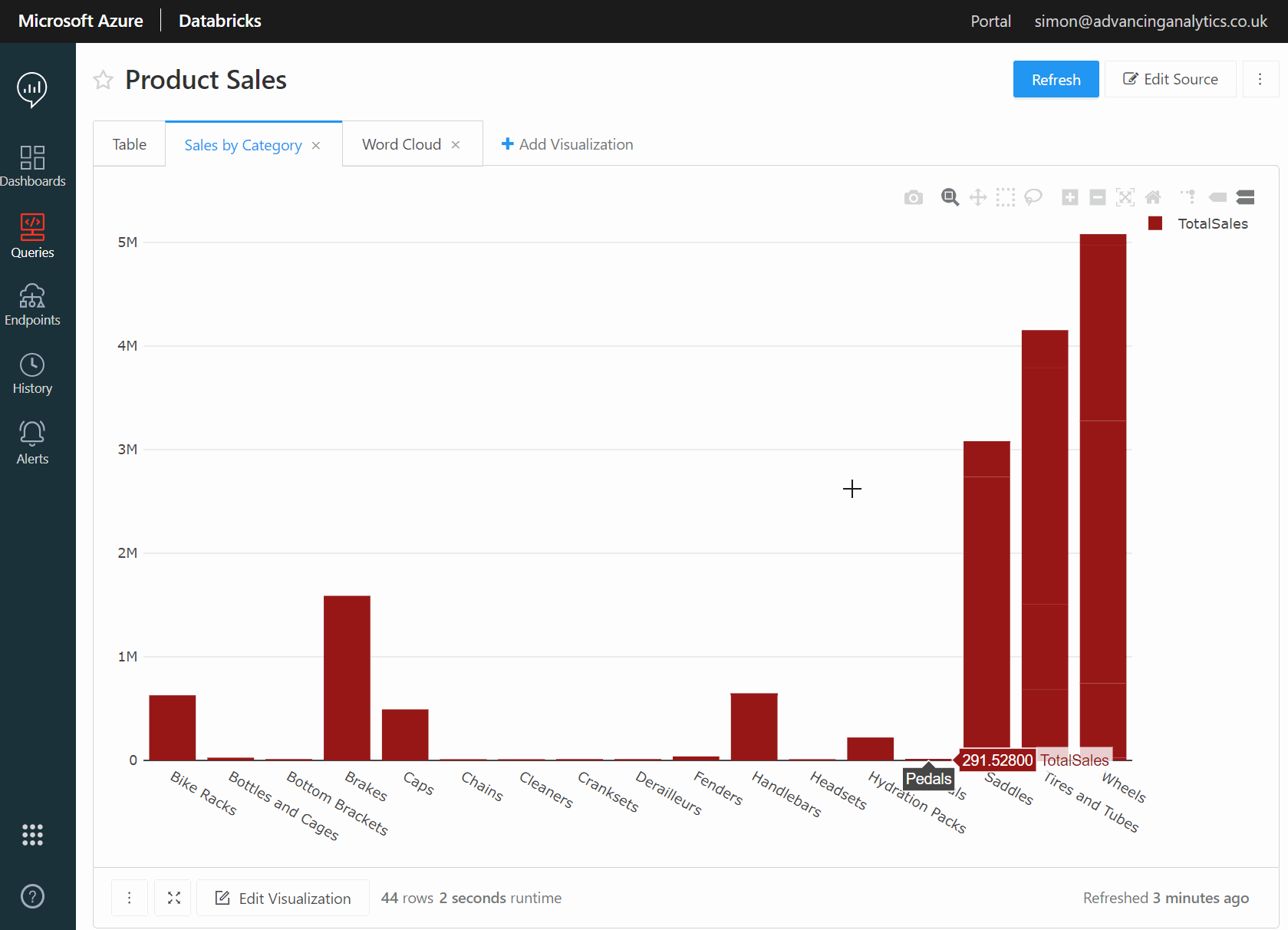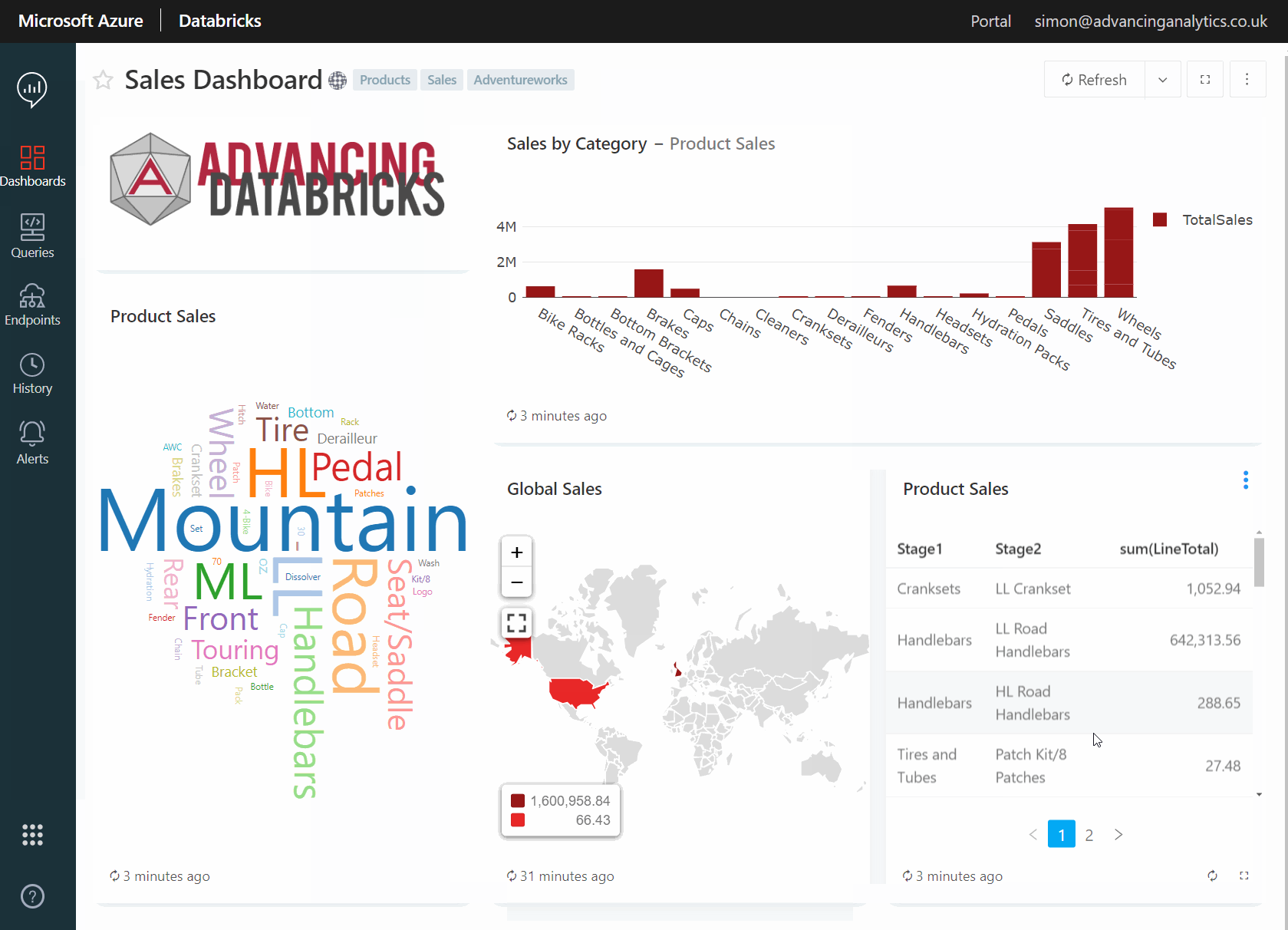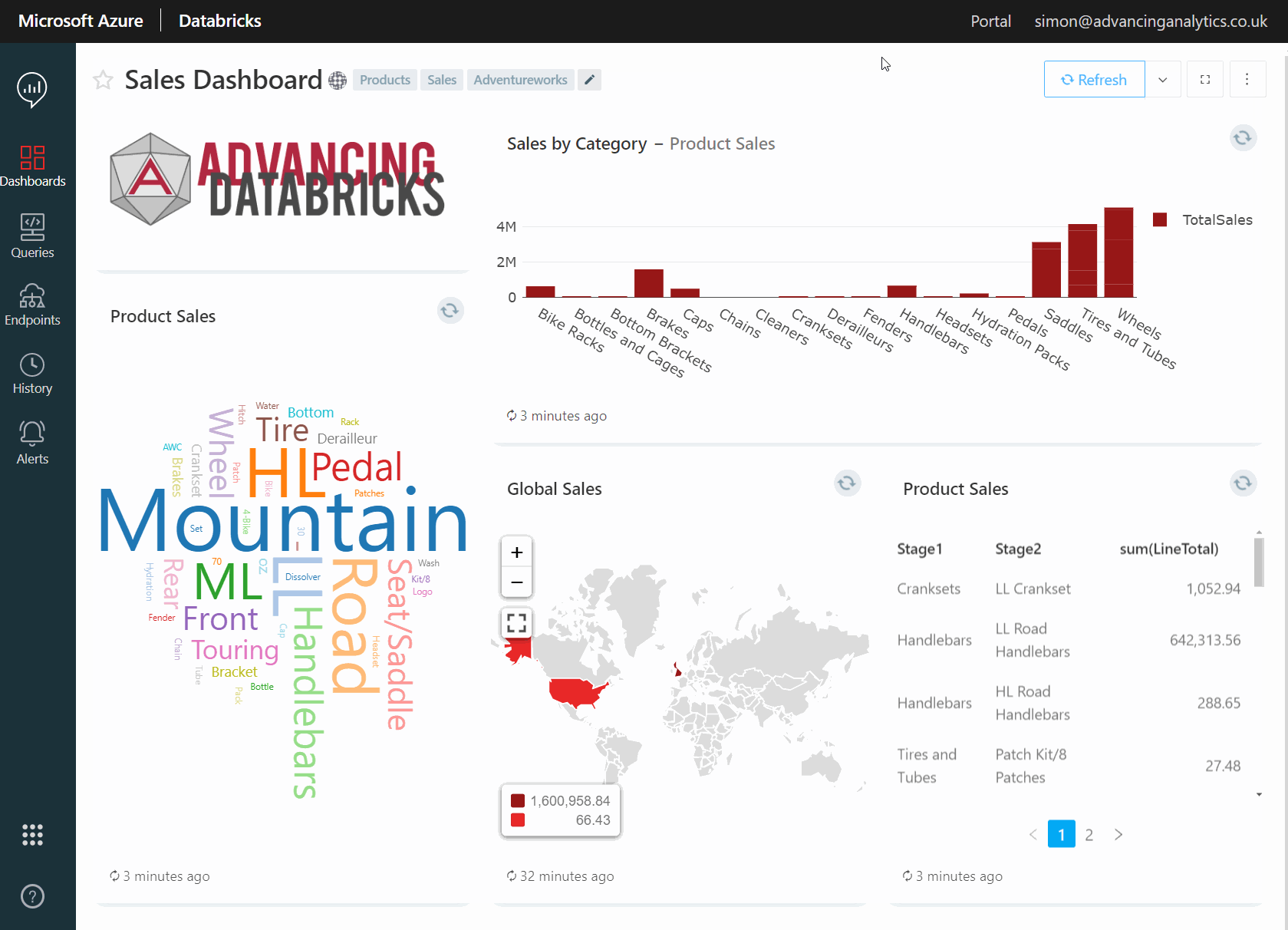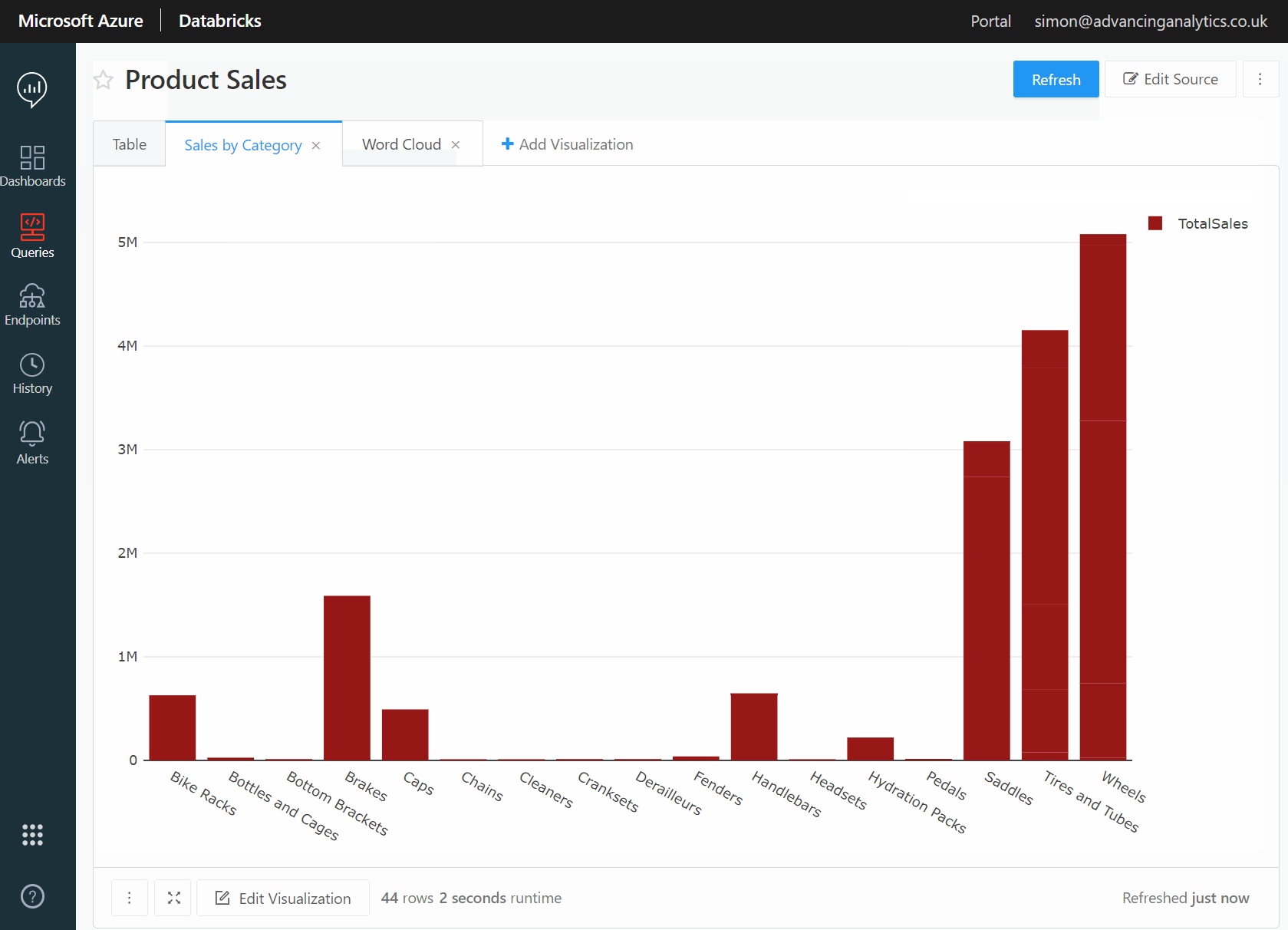
Databricks SQL Analytics in Action
BI Connectivity
We have been able to hook up Databricks to Tableau and Power BI for quite some time now, but it has never felt like a full first-party data provider. Expecting a report consumer to generate personal access tokens and construct a JDBC url path is asking a lot. The new SQL Analytics environment provides a new endpoint with a focus on simplifying connectivity, implementing security features such as single sign-on and optimising the connectors for runtime performance.
The message for the Lakehouse to be successful is very clear – it doesn’t matter how or where you perform your analytics, the Lakehouse has to offer no barriers to being the primary data source. Until now, with workarounds and quirks to BI tool connectivity, it hadn’t achieved this goal – with the new featureset we’re a lot closer than ever before, with a clear future direction.
Photon Performance
The final piece of the SQL Analytics puzzle is the implementation of the new photon engine. This is a major shift in how the Spark engine functions, moving from the Java-based platform to a C++ based solution. This switch, along with some of the frighteningly clever CPU vectorisation techniques previewed by Reynold Xin back at the Spark & AI Summit earlier this year, provides a platform for massive performance gains on top of the existing Spark engine.
This feature is going to be a huge help in achieving the aims of the report consumer persona – they aren’t going to be writing highly optimised dataframe operations, they’re going to be throwing the generated SQL of BI tools at the platform and expecting the same performance levels as an optimised data warehouse. The Spark ecosystem shines when performing at scale, querying many billions of rows to return previously inaccessible results; but the Lakehouse has to provide consistent, fast performance for a range of dashboard queries large and small.
The Lakehouse, Realised
“Is this the achievement of the Lakehouse vision and the death knell of the data warehouse as we know it?”
Well, in a nutshell, no.
It’s a vital and incredibly important step on the journey and will satisfy the reporting and analytics requirements of a huge swathe of user personas, but it’s not yet at the same maturity level that an enterprise data warehouse would expect. If an enterprise needs the deep security functions of SQL Server, features such as dynamic data masking, automated data classification or even the simple single-record-select performance of clustered indexes, this isn’t provided by the Delta engine and Databricks platform even in its new evolved state. But then, these features are fairly niche – it’s not every organisation that needs that level of control within their reporting structures. There could certainly be an argument to serve 80% of the org’s analytics from a Lakehouse architecture, with only the data models that require the additional maturity pushed into a warehouse layer.
Many of our clients find the cost of maintaining both lake and warehouse platforms prohibitively expensive. There is a huge amount of excitement within these organisations, where they can consolidate these platforms without losing the value of their highly skilled SQL teams, without re-writing thousands of lines of report logic and maintaining the investments they have made in their existing BI tools.
There’s also massive value in this new analytics environment being simply available as part of the existing Databricks platform. If you’re currently working on building out a lake-based data architecture, and haven’t yet got to building out the curated data models, you can build these models, without any additional technology or integration investments into your Databricks platform. If you then find you need the additional maturity features within a full relational warehouse, you can migrate the SQL code with minimal refactoring.
Here at Advancing Analytics, we are incredibly excited about the Databricks SQL Analytics launch, and we’ll be digging into various parts of the new platform over the coming months. If you’d like to know more about the Lakehouse Architecture, building modern analytics platforms or where to start on your cloud analytics journey – get in touch!

Data Platform Microsoft MVP You can follow Simon on twitter @MrSiWhiteley to hear more about cloud warehousing & next-gen data engineering.