


The Data Lakehouse – Dismantling the Hype
That’s right, we’ve entered a new decade, it’s time for a new buzzword to define what we’re doing… right? Enter the Data Lakehouse. Now this term isn’t entirely new – we’ve been talking about data lakes and data warehouses together for the better part of the last decade, it was only inevitable that people would portmanteau the two together, especially as we commonly build hybrid architectures that we refer to as a “Modern Data Warehouse”. Given we already have this phrase, I want to dig a little into why a new term might come about and whether it’s worth paying attention to.
A lot of the current hype is down to a recent post by Databricks themselves – the impressive lineup of co-authors (O’Reilly’s Chief Data Scientist Ben Lorica and Databrick’s terrifying braintrust of Armbrust, Ghodsi, Xin, and Zaharia) speaks volumes about how much weight Databricks are putting behind this term. They’re not the first to use it, it’s been thrown around by Snowflake and Amazon in the past two years, the first notable mention being way back in August 2017.
Modern Data Warehouse VS Data Lakehouse?
So let’s see – if we’ve been building hybrid solutions of lakes and warehouses for many years now, is this just a new term for the same thing?
I’m going to give it the benefit of the doubt and say actually… no. What we’re talking about is a shift in thinking that has been driven by technological advances but, crucially, isn’t ready yet.
First, the Modern Data Warehouse, which is an architectural pattern more than anything. Everyone who has managed a large data warehouse knows that there comes a tipping point when the whole thing becomes slow and inflexible. In software engineering terms, most data warehouses are gigantic monolith solutions – however data is moving faster than a traditional warehouse can handle, hence the adoption of data lakes, as I’ve argued previously.
Data Lakes themselves lack some of the more mature features we need for doing financial reporting and driving critical business decisions. Full data access audits, row level security, dynamic data masking or many hundreds of other enterprise security features we find in mature relational stores, simply aren’t easily available in Data Lake solutions currently.
That’s what led us to building out solutions following our reference architecture, a simplified version might look like this:
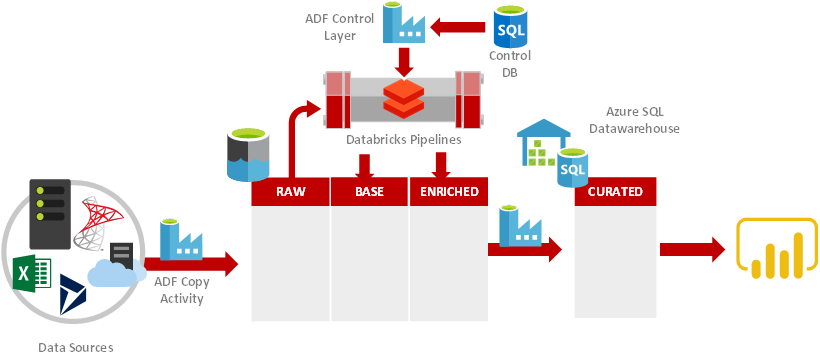
Figure 1 - Modern Data Warehouse - The Advancing Analytics Reference Architecture
Simply put – if you want the best of both worlds, then you need to include both worlds within your solution.
One of the key elements of this is the movement of data between the lake layer and the warehouse layer. We’re picking data up from it’s distributed, analytics-specialized format and inserting it into a different distributed, analytics-specialized format. There are a plethora of specialist Data Virtualization tools claiming that you don’t need to do this, but generally, they end up caching the data and you’re managing yet another data store and paying the price for it.
This is our current state – managing a solution with the complexity or two different analytics stores, so that we can gain the benefits of both types. The Data Lakehouse is challenging this notion.
With a Data Lakehouse, we keep all data within its lake format, it’s a common storage medium across the whole architecture. The tools that we use to process and query that data, are flexible enough to use either approach – the adaptable, schema-on-read querying that comes with engines like Apache Spark, or a more structured, governed approach like that of SQL Server.
Rather than processing our data in the lake, then sharing the data out to other tools for data science, traditional BI, ad-hoc analysis and more, we build a single data store that can handle all use cases. In their blog, Databricks visualize it as this evolution paradigm:

Figure 2 - Evolution of Analytics as seen by Databricks
For me, I’d talk about it in a much simpler manner:

Figure 3 - MDW & Lakehouse approaches compared
So to answer our original question – do we really need another term for a solution that is essentially delivering the functionality we’re striving for in existing architectures, I think we do. If we’re using “Data Lakehouse” to describe that end goal of a unified platform that delivers everything within our Modern Data Warehouse architecture but differentiates itself by the nature of the shared storage platform and convergence of tooling, I think that a new term has value. If anything, it puts a stake in the ground for the technical direction and future of the solutions that we’re developing.
Are we ready for Data Lakehouses?
This is the major question, and one that I’m answering with a resounding “No”. Or rather “They’re not yet ready for us”.
Whether we’re talking Databricks, the upcoming Azure Synapse, Snowflake, Amazon Redshift, none of the offerings are fully there yet. Adopting a single tool in their current state means making a lot of compromises and accepting reduced functionality… for now.
Databricks themselves talk of having a unified analytics platform – but there are elements that are way behind other vendors, and they know that. The Databricks platform allows you to create databases and relational objects, sure, but functionality-wise is years behind that of SQL Server. Our ability to manage complex schedules and workflows is very limited – on a par with SQL Agent, but nowhere near modern ETL tools such as Azure Data Factory. On its own, it won’t tempt the seasoned business intelligence professional away from a properly managed database solution.
Azure Synapse comes from the other side – we can see from the current overview that it’s taking Azure SQL Data Warehouse as a base and building out a single platform. It talks about integrating Apache Spark & the T-SQL engine, it shows PowerBI within the same workspace, we hear about code-free data orchestration and integrations. This is a lot closer to what we’d expect from an all-in-one platform… but it’s not available in public preview yet, and it’s likely the initial release of the spark engine will be closer to SQL Server Big Data Clusters than the full richness of functionality that Databricks add onto their runtime. Our clients that are deep into performance optimizing their spark processing, utilizing full Databricks Delta and in love with the rich management workspace, will take a lot of convincing to sacrifice these features for the simplicity that a single platform brings.
I’m admittedly not as close to the other offerings out there, but the story seems the same across the board. Most vendors have an area they’re very good in and they’re slowly trying to spread out to encompass the others but haven’t yet reached the nirvana that is feature parity.
So where does that leave us?
Currently, there’s no impetus to change – the Data Lakehouse ideal isn’t where we need it to be. We’re going to see something of an arms race over the next 12 months as various vendors try to be the first to market with a one-stop-shop for everything analytics.
For people who have complex problems to solve and a real need to do it, there’s no driver to change from the modern warehouse architectures we’ve been building. Yes, there are elements of complexity by managing different technologies together, but this is outweighed by the functionality these architectures unlock.
In the future, I think we’re going to see an initial split:
Companies whose requirements aren’t that complex that fall into the target market for the initial Data Lakehouse offerings, they’re not hampered by some of the functional compromises and they get a whole load of benefit without the technical barriers.
Companies whose analytics teams are already mature in these areas, who will resist transitioning, because they would sacrifice functionality they already have access to. These will drive the demand for the Lakehouse offerings to gain maturity quickly and push for more and more innovation in these areas.
Here in Advancing Analytics, the idea of the Modern Data Warehouse and emergence of the Data Lakehouse is going to be central to many of the conversations we’ll be having with clients in the coming months.

Would the all-in-one solution fit your needs, or do your unique challenges require the deeper functionality of separate systems? This is the kind of architectural conversation we’ll be having over the next year, and we’d love to hear your thoughts on it. Do you agree that the semantics of the Data Lakehouse is worth it’s own term, or should we stick to Modern Data Warehouse as a catch all for everything?
If you’re looking to adopt an Azure Analytics platform, or ensure your current one is reaching it’s full potential, there are many ways that Advancing Analytics can help you achieve your goals.

Simon Whiteley
Director of Engineering
Data Platform Microsoft MVP
You can follow Simon on twitter @MrSiWhiteley to hear more about cloud warehousing & next-gen data engineering.