

Choosing the Right Recommendation Algorithm
Introduction
Putting the right products in front of your customers at a time they are motivated to buy increases the bottom line. That could be which product is best placed when a customer is at the till, it could be what song you want to recommend on Spotify, or your next series to binge on Netflix. However, it could be something more complicated and more real world, such as recommending the next best action one of your customers should take. Recommendation Systems have been around a very long time and have gone through several different incarnations. There are many different approaches that you can take to building a recommendation system and in this blog, we want to explore a couple of different options that you have available.
Option 1: Collaborative Filtering (CF)
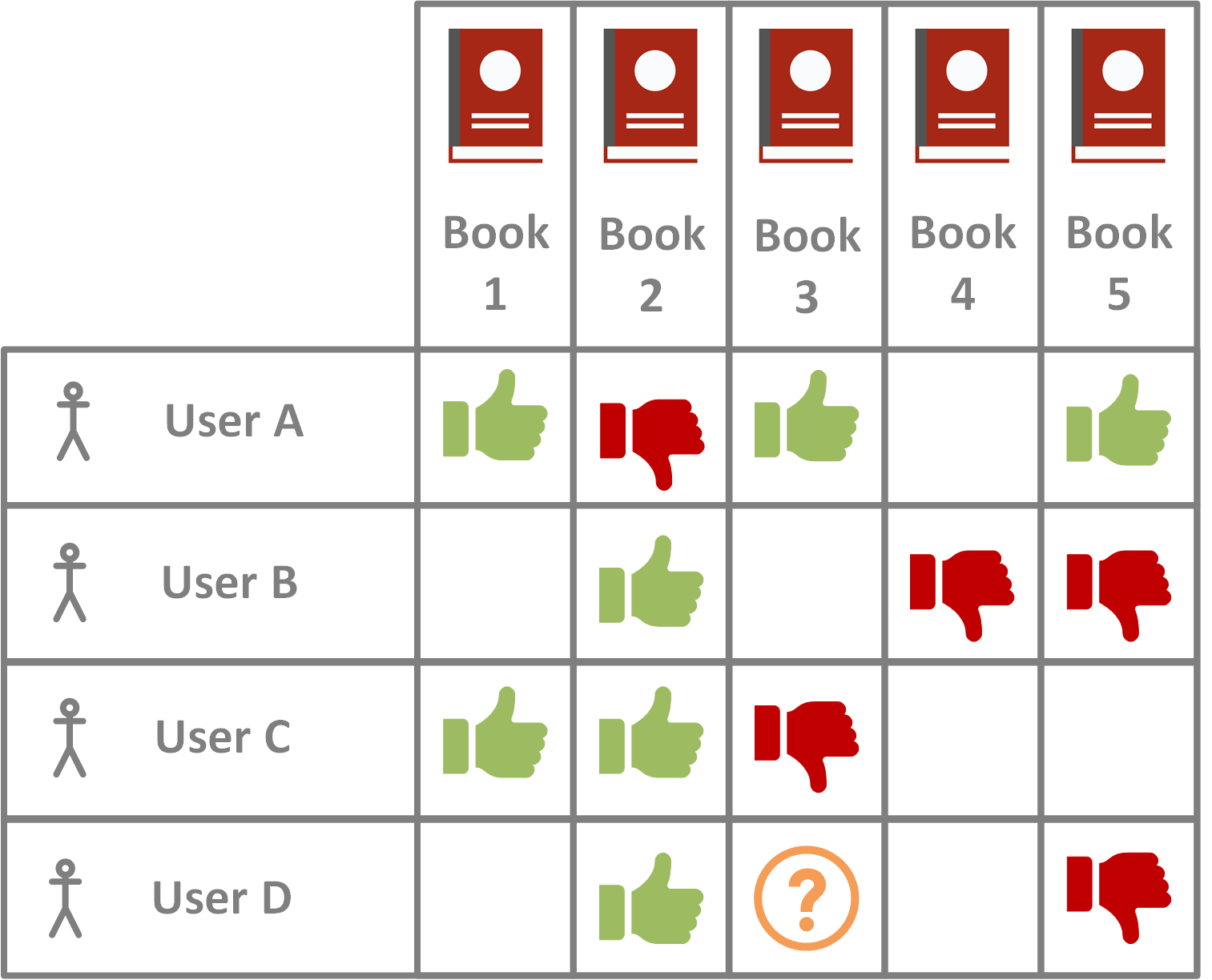
Collaborative Filtering
One of the most popular approaches to recommendation problems is Collaborative Filtering (CF).
This approach is based on the assumption that users who have agreed in the past, also tend to agree in the future. For example, if Alice likes Star Wars, Lord of the Rings and Harry Potter and Bob likes Stars Wars and Lord of the Rings too. Then it is likely that Bob would also enjoy Harry Potter. The collaborative in Collaborative Filtering is in relation to looking at the way that you multiple users interact with the same data and share the same commonalities.
This method relies heavily on historical interaction data. User-item interactions and item-item interactions. To give our interactions weight, we need a rating. A rating can be provided as either Explicit or Implicit.
Explicit Ratings are ratings supplied by the user usually on a scale (typically out of 10). This type of rating is rarer because it relies on users who are not always prepared to provide it. Despite this, it is seen as more reliable since it does not involve any inference. Examples of this could be imdb movie ratings, or the ratings provided on Goodreads.
Implicit Ratings, on the other hand, are interpreted from user actions such as the history of purchases, navigation history, and time spent on some web pages, links followed by the user, content of e-mail and button clicks, among others. This type of rating is more readily available because it requires no effort on the user’s part. This is similar to how Netflix make recommendations, after you watch a film, Netflix it doesn't ask you for your rating out of 10, however it does infer from how you have viewed films and what you particularly like.
There are several things to consider when choosing CF for your Recommendation system. Collaborative Filtering relies solely on historical interaction data, it greatly suffers from the ‘cold start problem’. This is where new users or items are added to the system with little or no ratings. How do you know to recommend an item when you have never seen how that item interacts with other users? This will quickly reduce performance of our recommendation system. There are a number of ways in which we can overcome cold starts, a very common way which you may have experienced before, is using a user survey to gauge an individual’s preference towards particular items and then use that to make recommendations initially.
Collaborative filtering is an approach that uses matrix factorization. We compute item pairs and user-item pairs by creating large, sparse matrices. You can imagine this being every item and every user and their individual ratings when you have a vector of 100 users and a vector of 100 items, we end up with a matrix of 100,000 cells.
The nature of building one big matrix filled with users and items creates two more problems. The first is scalability. Computation grows exponentially with the growth of the dataset. Collaborative filtering is often only efficient for a certain size of data. However, this can be resolved by using more scalable Collaborative Filtering algorithms such as Alternating Least Squares in Apache Spark. The second problem that arises from CF is sparsity. Not every user will interact with every item, in fact most of the entries in the matrix will be NULL values, often as much as 99%. This can affect the accuracy of the recommender by a significant amount.
Option 2: Content Based Filtering (CBF)

Content Based Filtering
Another popular recommendation method is Content Based Filtering (CBF). Content Based Filtering relies more on descriptions and features in the dataset over historical interactions and preferences. For example, if a user likes many items of a certain category, then they might like other items of that specific category. This makes it almost unaffected to both the ‘cold start problem’ and user preferences changes. Another advantage to CBF is that is a lot more explainable than Collaborative Filtering. It is possible to trace why a certain recommendation is made because it uses patterns in features and doesn’t try to infer hidden user preferences.
However, they do suffer from overspecialization when users begin to only receive recommendations similar to items they have already encountered and won’t be recommended something new that they might like. The one major disadvantage to CBF is the need to have an in-depth knowledge and description of the features of the items in the profile which aren’t always readily available.
Option 3: Graph Recommendations
Graph Recommendations involve modeling the data into a Graph structure and creating recommendations based on traversing the links between users and Items. This is probably the least ‘sophisticated option’ but it’s simplicity will eliminate the ‘cold start problem’ and it handles both Explicit and Implicit ratings with almost equal accuracy. The Random Walk method will start on either a User or Item node and randomly traverse different routes to another node in the Graph to calculate the similarity between the two nodes and make its recommendation on this. A random walk is a process in which you start at one node in a graph, and at random traverse nodes based moving in a random direction. For more information on random walks, we recommend reading our blogs around Monte Carlo model simulations.
Alternatively, the Link Prediction method, will identify where links between Users and Items will happen in the future and use these as their recommendation. Both of these methods are unfortunately a little more hands on than either CF or CBF, requiring a thorough knowledge of both Graph Theory and the dataset itself. Similar to CBF, it’s easy to overspecialize a Graph Recommender and always recommend similar items. Special care needs to be made to counteract this.
It is not uncommon for Graph Recommenders to be combined with other Machine Learning techniques such as Regression to calculate the similarity between Items and Users. This leads us onto our final option:
Option 4: Hybrid Recommender Systems
Hybrid recommenders can consist of a combination of any of the above-mentioned techniques and other machine learning techniques much like the Graph Recommender and Regression approach. If done correctly, you can combine the positives of the above techniques and reduce the negatives such as ‘cold start’ and speed. State of the art recommendation systems rely heavily on a combination of collaborative based filtering and content-based filtering.
Comparison
As covered above, there are many things to consider when selecting which recommending technique to implement. To help, we have made this handy diagram below:
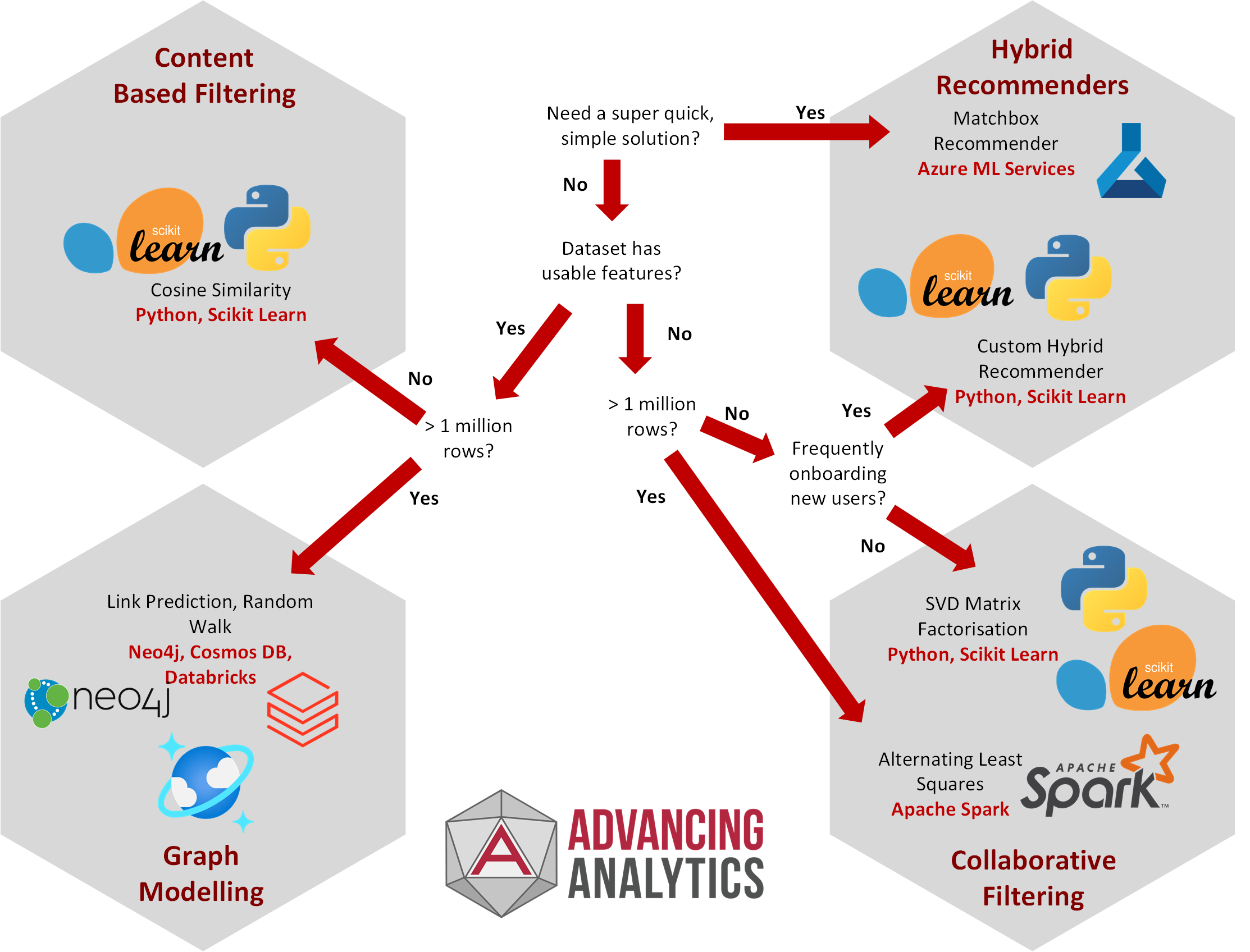
Choosing the Right Recommendation Algorithm
Conclusion
It is seldom the case that one recommendation algorithm is enough to make real world recommendations. Much like most machine learning scenarios it takes one ensemble of models working together to get closer to reality. A good ensemble of models is one which overcomes common issues and makes recommendations which are relevant to the customer overall but also relevant to the customer’s needs and demands at that point in time.
If you think a recommendation system could help focus your customers behaviours and uplift your bottom line, then please get in touch we'd love to talk about building recommendation systems for real world scenarios.