

Writing a Single JSON File in Databricks
When writing to a JSON destination using the DataFrameWriter the dataset is split into multiple files to reflect the number of RDD partitions in the dataframe when in memory – this is the most efficient way for Spark to write data out.
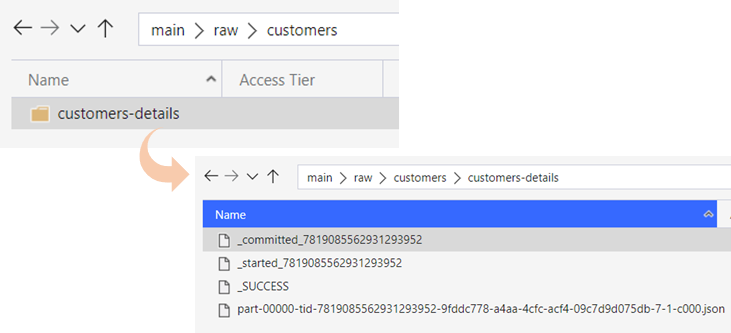
However, this creates a directory containing the data files, as well as Spark metadata files…but what if you just wanted a single JSON file? It’s a scenario that comes up a lot with our clients and, despite it not being the most efficient way to use Spark, we need to implement it all the same.
The following query takes a dataframe and writes it out as JSON, this will create a directory with multiple metadata files and JSON file with a partition name.
The coalesce command is used to reduce the number of RDD partitions in the dataframe. You could also use .repartition(1), however coalesce will try to combine RDD blocks in memory on the same worker, reducing the need for shuffling.
dataLakePath = "/mnt/adls-main/raw/customers/customers-details-partition"
# Write data to single partition
( df
.coalesce(1)
.write
.mode("overwrite")
.json(dataLakePath)
)
Workaround
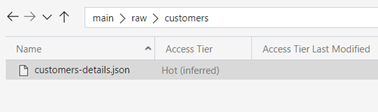
In my scenario, I just want a single JSON file without the _"committed", _"started" and _"SUCCESS" metadata files and without the directory. To achieve this, I will add few additional lines of code that will move the JSON file out of the directory, rename it then remove the redundant metadata files and directory.
Firstly, get a list of all files from the directory
Finally, remove the metadata files and directory.
dbutils.fs.rm(dataLakePath, recurse = True)
Finally, remove the metadata files and directory.
dbutils.fs.rm(dataLakePath, recurse = True)
Finally, remove the metadata files and directory.
dbutils.fs.rm(dataLakePath, recurse = True)
This will generate a single JSON file
Summary
Using the DataFrameWriter API can be frustrating when you want a single JSON file written out from a dataframe. It’s a really simple scenario in many other tools, but the parallel nature of Spark simply doesn’t work that way – so we need to work around it.
This simple workaround uses the Databricks utility libraries to move the files from the directory, rename and remove any old metadata files and the now-empty directory. If you’re not in Databricks, you can perform similar actions using shell commands directly from the driver.
This coalescing approach is not the most efficient method when you have large datasets - as to write out a single file, Spark needs to gather all the data on a single worker and write it out using a single CPU. In cases where you have relatively large datasets, you should always let Spark write out multiple files this will ensure you avoid memory issues and performance problems.
However, sometimes these scenarios come up, and it’s always useful to have pattern that you can use.
I hope you found this useful and helpful.
Reference
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrameWriter.json.html