

UNDERSTANDING RECOMMENDATION ENGINES

Source: ActiveState
At present, recommendation engines have gained popularity within the businesses and e-commerce world. Companies now make use of recommendation engines to provide personalised suggestions to their customers. These recommendations make it possible for customers to be provided with suitable suggestions for items they have not yet seen.
What are recommendation engines?
Recommendation engines are a system that gives suggestions or predictions of products, services or information users would be most interested in based on data analysis. The analysis could be based on the history of the user or the behavioural patterns of similar users.
These engines are used by companies in various lines of work, which span from marketing to e-commerce to the entertainment industry. Businesses have come to realise that the exponential increase in the amount of digital information has brought about challenges of information overload. These challenges have brought about the need for a personalization algorithm to give users suggestions they would most likely be interested in. This has been seen as beneficial for businesses since a good recommendation engine can increase revenue.
Why do we need recommendation engines?
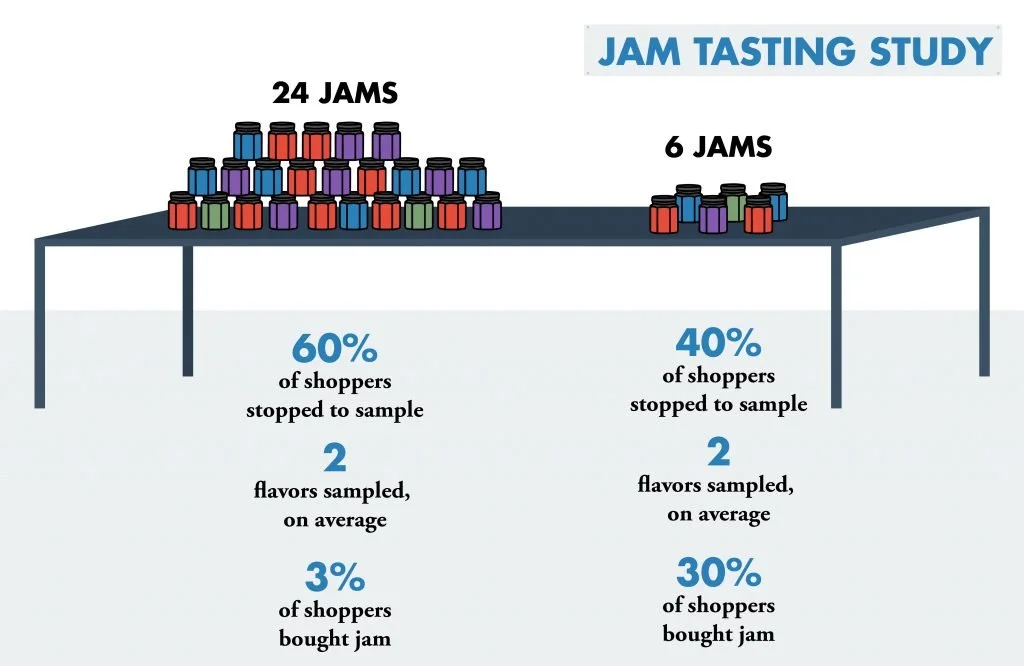
Source: comparison
An experiment was conducted in the year 2000 by two psychologists called the “Jam experiment”. Customers shopping at a grocery store in a food market were presented with a tasting booth that showcased 24 varieties of jam on a regular day. This same booth later showcased only 6 varieties of jam every other day. The aim of the research was to find out which of these would drive more sales, the assumption was that there will be an increase in sales when the booth was showcasing 24 varieties of jam. However, a bizarre phenomenon occurred when the booth had 24 varieties of jam, it generated more interest but the conversion to sales was very low. The conversion to sale when the booth had 6 jams was 10 times higher. It was concluded that too few choices may be bad, but too many choices would be worse. So how do we balance and provide reasonable choices for users?
With the help of data analysis, recommendation engines can filter through the large data available and provide reasonable choices the customer can relate to in a matter of seconds. This can lead to an increase in the number of customers and can as well help with customer retention which gives the end goal of an increase in revenue.
Types of recommendation engines
There are 3 types of recommendation engines, they are:
- Content-based filtering
- Collaborative filtering
- Hybrid Model
CONTENT-BASED RECOMMENDATION ENGINE:

Source: Ariflaksito
This type of recommendation system gives suggestions based on the attributes of an item. The idea is to find out what items the User has previously been interested in, then look up and recommend other items with similar attributes to the user. This type of system depends on two sources of data, data which includes the various items in terms of content-centric attributes and the user profile which could be created by feedback on various formerly viewed or used items. Unlike collaborative filtering, other users have no impact on suggestions from this type of recommendation system.
In implementing content-based filtering, different approaches can be used. Pandas can be used as well as PySpark which takes advantage of distributed memory for faster analysis on very large datasets. Some of the algorithms that could be used to determine the similarity between items are:
- Cosine similarity
- Euclidean distance
- Pearson’s correlation
COSINE SIMILARITY:
This algorithm mathematically calculates the cosine angle formed by two vectors projected in a multi-dimensional space. It determines the similarity between two documents regardless of their size.
EUCLIDEAN DISTANCE:
This algorithm is mostly used to solve clustering problems, it’s the shortest distance between two points based on the Pythagorean theorem. The distance between two items is referred to as the score, if the score of a distance is zero, that means the items are the same. Euclidean distance is a metric for geospatial problems, it can determine distances in both two and three dimensions.
PEARSON’S CORRELATION:
This algorithm measures the power of a linear relationship between two variables. It can be said to be the representation of two sets of data’s linear correlation.
The examples of algorithms stated above can be used on a Pandas DataFrame. For the Spark fans, one algorithm that can be used on the Spark DataFrame when it comes to content-based filtering is the Bucketed Random Projection for Local Sensitive Hashing.
LOCALITY-SENSITIVE HASHING:
Locality Sensitive Hashing is an algorithm that hashes similar items into the same bucket, with a high degree of certainty. This algorithm can very much be used for clustering and nearest neighbour searching. It varies from the traditional hashing techniques in that it maximises rather than minimises hash collisions. Codes and steps for using LSH for recommendation engines will be discussed in further blogs.
ADVANTAGES OF CONTENT-BASED FILTERING
- No information is needed about other users
- It recognises users interests and makes recommendations pertaining to that particular user
- It resolves the “cold start” problem as items can be suggested before being rated by other users
LIMITATIONS OF CONTENT-BASED FILTERING
- Users may only see items similar to what they’ve already experienced, so suggestions on different types of items won’t be recommended for users to try out.
- The accuracy of this type of recommendation is based on adequate knowledge of the item.
COLLABORATIVE FILTERING:

Source: recommender
This type of recommendation engine relies fully on data containing user ratings to suggest items to other users. It makes use of a collection of behavioural data from other users to accurately recommend items to users. Collaborative filtering works on the basis that we as humans usually would listen and receive suggestions from other people we believe share the same views, opinions or tastes as us.
To implement collaborative filtering, the alternative least square method can be used. You can take advantage of the distributed nature of Spark to parallelise this algorithm by using the PySparks version of this routine.
There are two ways collaborative filtering can be done, they are:
- User-based collaborative filtering
- Item-based collaborative filtering
User-based collaborative filtering:
This type of collaborative filtering searches for users whose behavioural patterns are similar to yours and suggests items that interest them that you haven’t tried or seen yet. For example, for user A, user-based filtering searches for other users B, C, D, E, and F that have rated items the same way as user A, then searches and recommends other items that users B, C, D, E, F have rated that user A has not come across to user A.
Item-based collaborative filtering:
This type of collaborative filtering searches for items similar to items already rated by the user. An item-item matrix is created to understand the relationship between items. Using this matrix and the behavioural data of the user, items can be recommended to the user. This approach is very much used by Amazon.
ADVANTAGES OF COLLABORATIVE FILTERING:
- No need for domain knowledge as the embeddings are automatically learned.
- It recommends new items of different attributes to users, unlike content-based filtering which recommends items of similar attributes.
- Changes in user preference can be captured easily.
LIMITATIONS OF COLLABORATIVE FILTERING:
- When data is inadequate, the accuracy of the recommendation is affected.
- The “cold-start” problem. This occurs when too little is known about a user, especially a new user, and it becomes harder to accurately recommend items to them.
HYBRID RECOMMENDATION SYSTEM:
The limitations of the above recommendation engines brought about the need for a hybrid system, that encompasses the embedding of both content-based filtering and collaborative filtering. This method can be applied in various ways, including applying content-based filtering to a collaborative approach and unifying them into a single model.
Many of us have noticed this approach being used. Let’s take Spotify which is a music entertainment platform for example. When you join as a new user, information about the kind of music you are interested in is first collected as well as the artists you fancy the most. Music recommendations are then made and suggested to you on this basis. Over time as you continue to use the platform, the system learns about you. It picks information about your behaviour and then finds other users similar to you to provide you with a more profound recommendation. In this scenario, the issue of cold-start is resolved. This type of recommendation engine is used by various businesses.
Conclusion
Recommendation engines are good and necessary as they drive sales for businesses, using this engine for your business has its perks. Building a content-based recommendation engine can be more challenging as deep domain knowledge is necessary and it could very much involve a lot of computational issues. For this reason, most businesses tend to go for collaborative filtering because of the ease of building it. But for a more profound recommendation the Hybrid system seems to be the best type of recommendation engine.