


Bringing Fabric to your Data Lakehouse
We've built countless Lakehouses for our customers and influenced the design of many more. With the advent of Fabric, many organisations with existing lakehouse implementations in Azure are wondering what changes Fabric will herald for them. Do they continue with their existing lakehouse implementation and design, or do they migrate entirely to Fabric?
For many, the answer will be to continue as-is. They've invested a lot of time and money in establishing a Lakehouse - to migrate now to a slightly different technology stack would be a very costly exercise! There also isn't a need to migrate from a lakehouse implementation in Databricks to one in Fabric as there aren't concrete benefits to be realised.
For those using Power BI as their semantic and reporting layers, as well as using Databricks SQL or Synapse Serverless as the serving layer, Fabric provides a perfect opportunity to rationalise the architecture and to bring about substantial performance gains through the Direct Lake connectivity and V-Order compression in Fabric.
Previously
With existing Lakehouse implementations on Azure, and a Power BI analytics front-end, the pattern for moving data between a Databricks Lakehouse and the semantic and reporting layers in Power BI would look like the following:
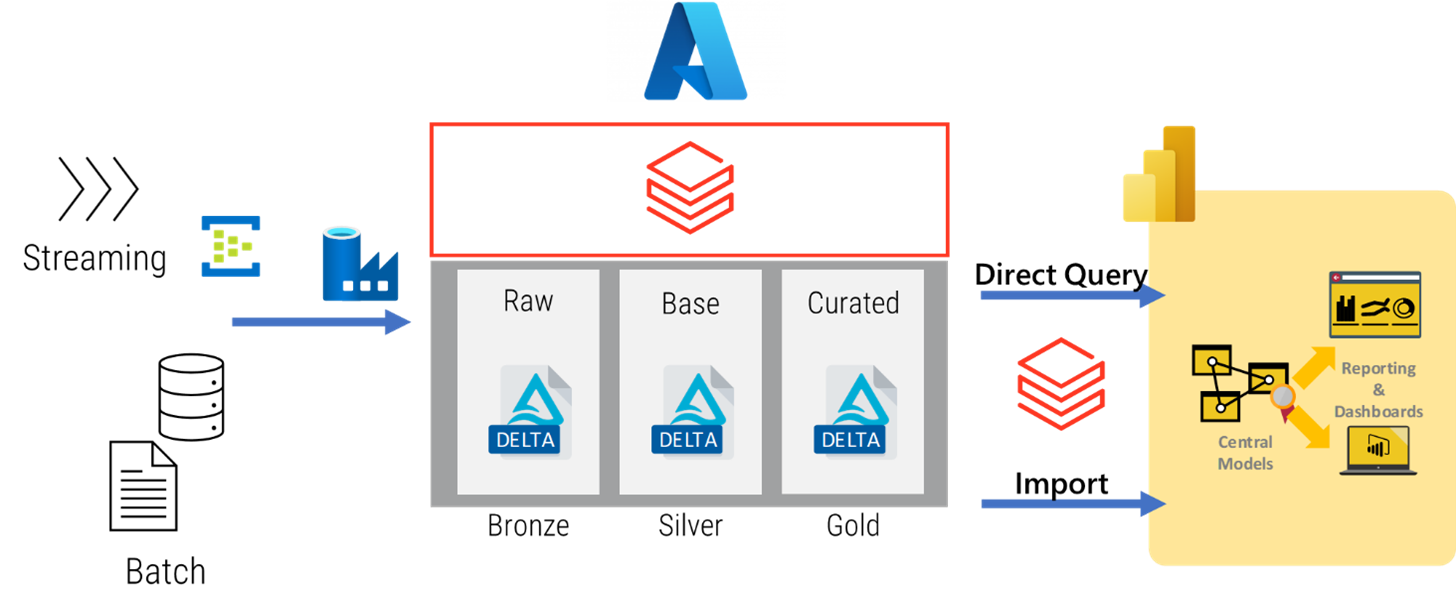
Physical curated data, in the form of a delta table is exposed to Power BI through a serving layer and views. The data is then imported into Power BI or queried using Direct Query.
While the architecture is fairly simple, it does mean that you have to design and implement a full set of integration patterns to handle different data volumes and velocities. You'd have to give careful consideration to the different serving layer options.
The Recent Future
With Fabric, we can simplify the whole architecture from Serving through to Reporting, without compromising on speed or cost either.
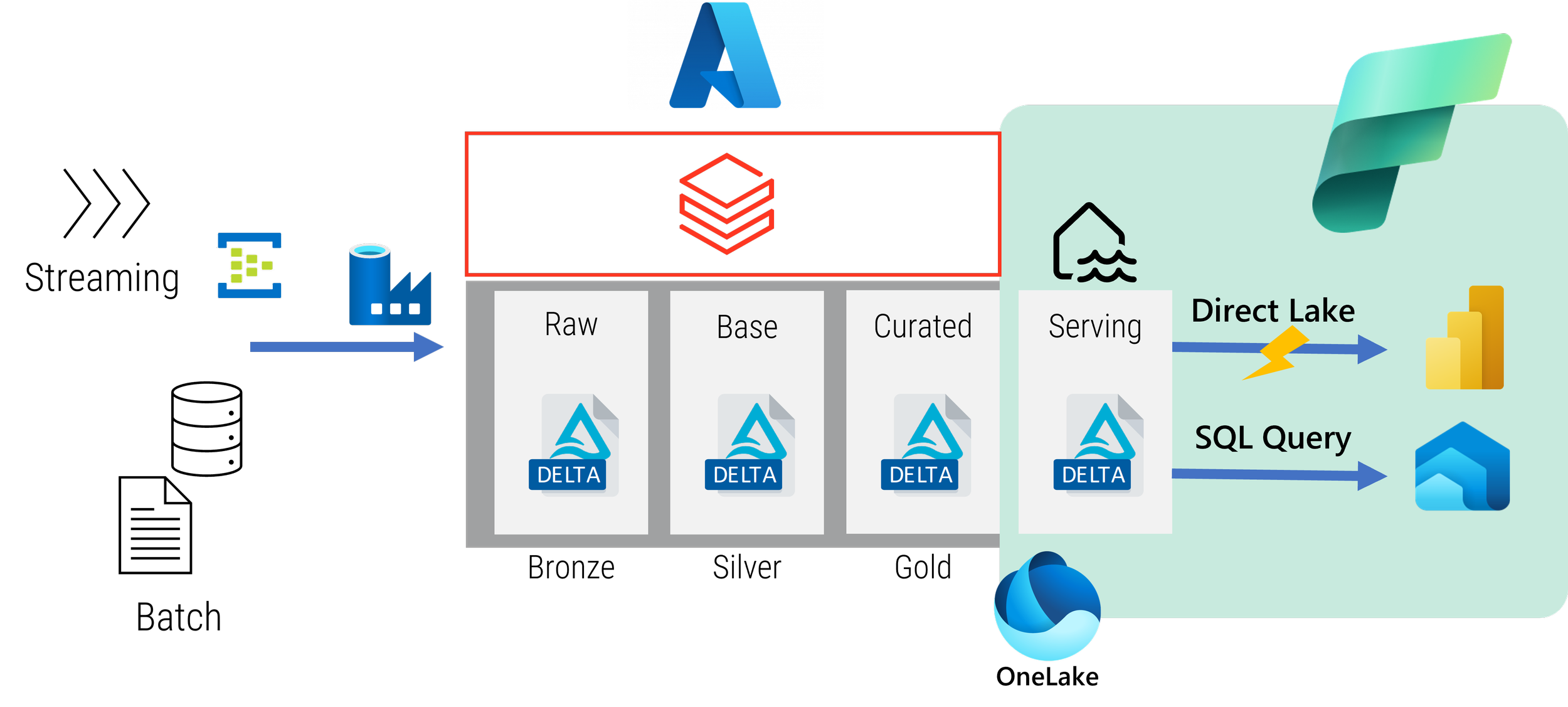
While we can keep the source to curated / gold processes within an existing lakehouse, we can move serving out and into Fabric and the OneLake.
As Curated / Gold is stored in the Delta format, this means that it can be referenced and read by Fabric as a shortcut, with the result of the serving logic (removal of audit columns, perhaps some simple filtering) written down into OneLake as a V-Ordered optimised Delta file so that Power BI can reference it directly within the semantic layer using a new feature called Direct Lake. This means that the objects for serving, semantic and reporting are one and the same. No need to additionally trigger a refresh of a Power BI dataset, as the data has been refreshed as part of the write action. It also means that users who still want to execute SQL queries against the serving layer can still do so - because Fabric also contains SQL endpoints for read-only queries.
Direct Lake also means that you get the benefits of both Import and Direct Query modes without any of the performance trade-offs and drawbacks.
The benefit of serving data through Fabric and a V-Ordered optimised Delta file is that, for dimensional modelling, there is greater compression of the data - which means quicker reads, lower latency across networks and lower storage costs.
The question remains: why stop at moving Serving to Fabric? Why not the whole Curation workload or, indeed, the entire Lakehouse process?
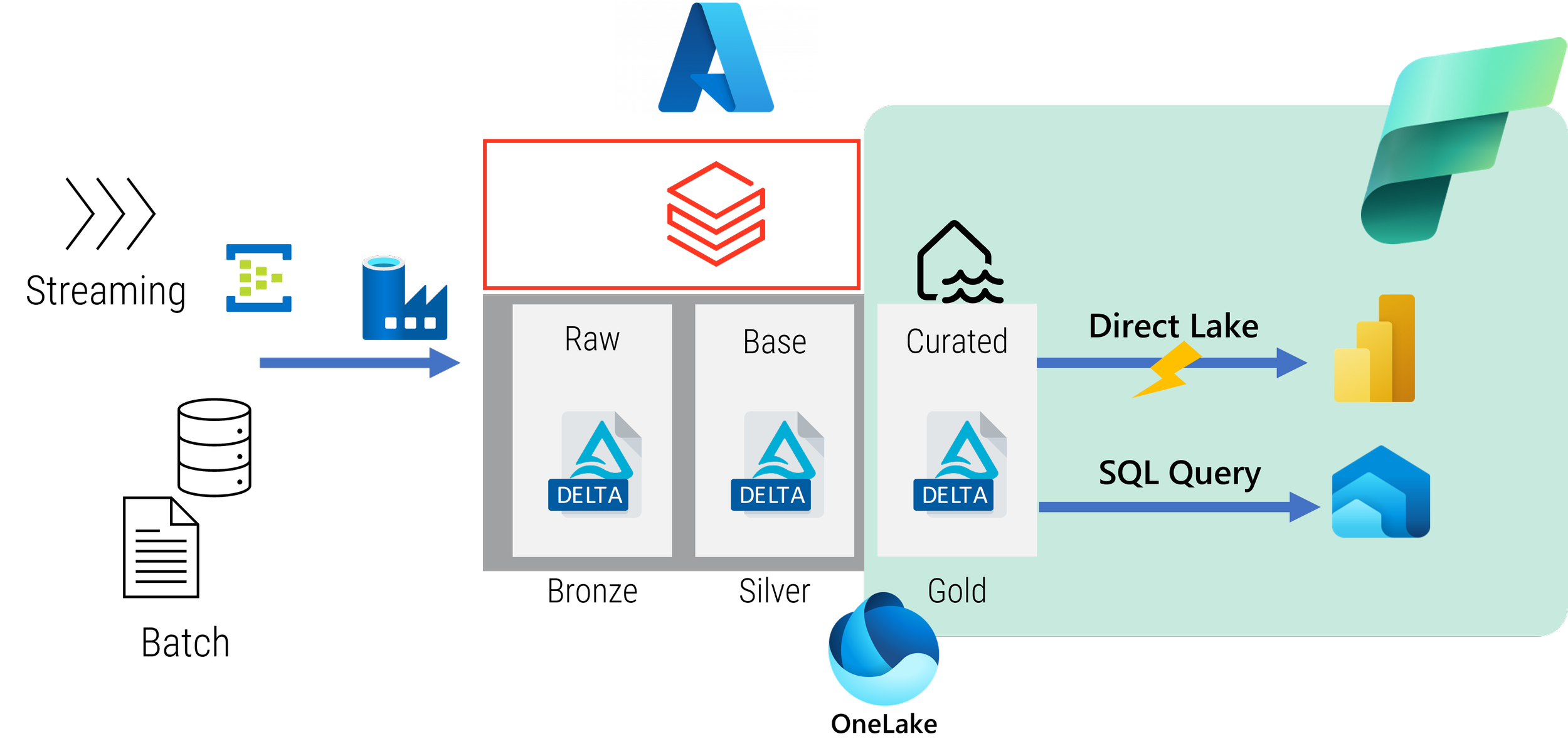
The serving process is, and should be, very simple and is easy to move - especially as the benefits outweigh the costs. Moving a curation process can involve some complexity, as not all features that you've made benefit of in Databricks will be available in Fabric, and vice versa. Databricks also provides more flexibility and visibility in terms of the compute used for the curation and engineering processes, allowing you to use more approaches to your data and analytics engineering pipelines, such as using the photon engine or delta caching.
If your curation process doesn’t use Databricks specific features, it is a perfect candidate for migrating fairly easily into Fabric and, therefore, simplifying the architecture even further.
Conclusion
As we've seen, if you already have an existing Azure Lakehouse implementation there is a clear and easy benefit of moving the Serving workload to Fabric as it simplifies the architecture and integration patterns between curated and semantic, speeds up analytical queries, and reduces overall cost of ownership.
Databricks and Fabric are two tools in your Lakehouse that work incredibly well together due to the different features and capabilities that they both have.
If you want to start leveraging a combined Databricks and Fabric Lakehouse architecture the next step is to contact the Lakehouse experts at Advancing Analytics.
Check out our other blog posts on Fabric: