


Will Koalas replace PySpark?
One of the first of many big announcements at the 2020 Spark and AI Summit was the official release of Koalas 1.0, the pandas API on top of Apache Spark.
This blog will explore how Koalas differs from PySpark.
Pandas and Spark

To understand what makes Koalas so important, you need to understand the importance of pandas.
Pandas is one of the major python libraries for data science. It is considered one of the 4 major components of the Python data science eco-system alongside NumPy, matplotlib and scikit learn. It has inbuilt functions to perform data manipulation and statistical analysis on Dataframe objects. Unfortunately, pandas isn’t totally scalable. Pandas is a pure python implementation, which means when running in Spark everything is run on a single workerworker, rather than across multiple. For particularly large datasets, pandas will run extremely slow and usually result in OOM errors.
This is, historically, where Spark steps up. Apache Spark’s implementation of Dataframe objects was first introduced in version 1.3 and was heavily inspired by pandas dataframes. It’s distributed nature makes it far more suited for fast processing of large datasets.
Pandas syntax and PySpark (Spark’s Python API) Syntax differ to a considerable degree. While PySpark has been notably influenced by SQL syntax, pandas remains very python-esque. PySpark is considered more cumbersome than pandas and regular pandas users will argue that it is much less intuitive.
Koalas

This is where Koalas enters the picture. Koalas is a pandas API built on top of Apache Spark. It takes advantage of the Spark implementation of dataframes, query optimization and data source connectors all with pandas syntax.
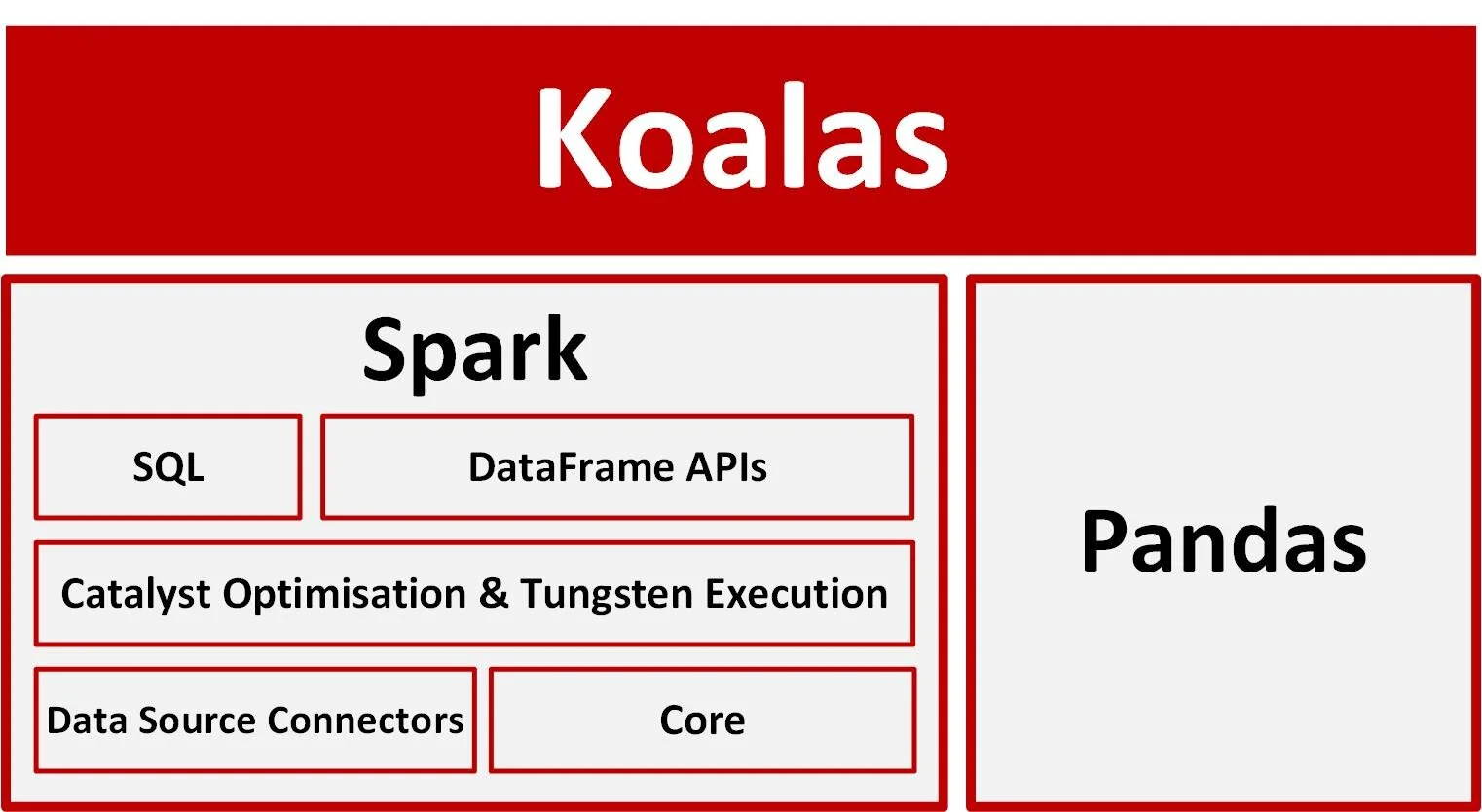
There are a lot of benefits to use Koalas over Spark, I will cover the most significant.
Familiarity
The most immediate benefit to using Koalas over PySpark is the familiarity of the syntax will make Data Scientists immediately productive with Spark. Below is the difference between Koalas and pandas.

To change to koalas all you need to do is change the library from pandas to Koalas. This will allow data scientists take any pre-existing code they have in pandas and convert it to Koalas within minutes.
Mutability
One significant difference between Spark’s implementation of Dataframes and pandas is its immutability.
With Spark dataframes, you are unable to make changes to the existing object but rather create a brand new dataframe based on the old one. Pandas dataframes, however, allow you to edit the object in place. With Koalas, whilst still spark Dataframes under the hood, have kept the mutable syntax of pandas.
It does this by introducing this concept of an 'Internal Frame'. This holds the spark immutable dataframe and manages the mapping between the Koalas column names and Spark column names. It also manages the Koalas index names to spark column name to replicate the index functionality in pandas (covered below). It acts as a bridge between Spark and Koalas by mimicking the pandas API with Spark. This Internal Frame replicates the mutable functionality of pandas by creating copies of the internal frame but appearing to be mutable.

Indexing
As mentioned briefly above Koalas also replicates the indexing functionality of pandas by managing an Internal Frame. This functionality does need to be used with slight caution in order to take full advantage of the Spark distribution. There are 3 types of indexing in Koalas.
Sequence Indexing
By default Koalas will index your dataframe using Sequence Indexing. This method is the exact pandas replication of implementing indexes by increasing the index one by one. To achieve this using Spark under the hood, it uses a window function without specifying a partition. This will likely force the entire dataframe onto a single node which will be slow and likely to invoke OOM errors. It’s advised to avoid this method when the dataset is particularly large.
Distributed Sequence Indexing
Another type of indexing is Distributed Sequence. This once again tries to replicate the pandas method by increasing the index by one each time but this time in a distributed manner. Under the hood, this utilises Spark’s GroupBy and GroupMap functionality. While this still results in a sequential order of the index increasing by one each time, if new data is added, it is not guaranteed to continue from where it left off.
Distributed Indexing
The final implementation of indexing doesn’t replicate pandas indexing at all. Distributed indexing uses the spark function 'monotonically_increasing_id' which makes the index non-deterministic and not sequential. While this is the most performant method, it removes the possibility of using indexes in join conditions.
Current Koalas State
Currently Koalas is undergoing bi-weekly releases with a very active community. All the most common pandas functions have been implemented in Koalas but there still lies a lot of functions that aren’t. The current state is as follows:

Will Koalas replace the need for PySpark?
It i’s unlikely that Koalas will replace PySpark. The release of Koalas will most benefit those already working with pandas and allow them to get started with larger datasets straight away or convert previous code into a more scalable solution. But there is still a significant chunk of pandas functionality still missing.
For those people already using Spark Dataframes, there is little incentive to move over and adopt Koalas . New functionality like mutability and indexing won’t provide any additional benefits to those used to working without it. However, Koalas does offer basic statistical analysis functionality that PySpark currently does not, such as calculating standard deviation and plotting. It could be, with future releases, that Koalas becomes the standard for distributed Data Science whereas PySpark will likely remain the preference for Data Engineers.